MI SELECCIÓN DE NOTICIAS
Noticias personalizadas, de acuerdo a sus temas de interés



Agregue a sus temas de interés
Con la colaboración de Nelson Vera
La llamada Inteligencia Artificial (IA) ha evolucionado hacia los temas de Machine Learning (ML) y Deep Learning (DL) durante la última década. Esto ha sido posible gracias a significativos avances en los sofisticados algoritmos, desde su nacimiento en las universidades de Dartmouth y Carnegie Mellon de los Estados Unidos en los años sesenta.
Sus avances se han extendido hacia modelos predictivos que bien compiten con la econometría tradicional. Sin embargo, las técnicas ML aún no están tan diseminadas como las de series de tiempo que tuvieron su apogeo durante los años ochenta y que merecieron el Premio Nobel de Economía de 2011 en cabeza de Sargent y Sims (ver Comentario Económico del Día 23 de abril de 2014).
Como veremos, las nuevas técnicas predictivas se asemejan a los modelos a-teóricos que explotan la riqueza de la información disponible sin previamente pensar en sus sistemas de causalidad o retroalimentación. En particular, veremos las ventajas de algoritmos-ML vs. las técnicas de regresión lineal, pero donde se tiene la limitante de requerir datos masivos para hacerlos aplicables al mundo macrofinanciero.
Machine Learning revolution
El ML es un método analítico que automatiza la especificación de los modelos de predicción; son modelos que “aprenden”. Este esquema difiere de la anterior “programación condicional” (tipo “if-then”). Su alta capacidad informativa le permite, por ejemplo, conducir autos (TESLA, Google), imaginar el gusto del consumidor (Amazon, Netflix) o agilizar procesos financieros (fintech), ver Informe Semanal No. 1402 de marzo de 2018. Estos procesos se apoyan en programación digital que replican el comportamiento del cerebro humano de “aprender con ejemplos” (ver Lee, 2018, AI Superpowers: China, Silicon Valley, and the New World Order). Aun para tareas sencillas como reconocer un gato, se requieren sofisticados algoritmos, pues se trata de pasar de la tarea de “identificar” a la tarea de predecir, ver gráfico presentado.
Econometría y Machine Learning
La econometría ha ido sofisticando sus herramientas estadísticas, pasando de mínimos cuadrados a las técnicas de variables instrumentales, modelos probabilísticos y vectores autorregresivos.
Estas técnicas combinan teoría económica con aprendizaje sobre comportamiento de las variables (como ya lo explicamos). Sin embargo, el ML puede producir estimaciones sesgadas (erróneas en promedio), pero de menor varianza. Tal vez el elemento más valioso del ML proviene de su carácter predictivo con base en sus insumos, sin necesidad de alimentarlos con “variables fuera de muestra”, aunque esto implica limitaciones operativas (ver Agrawal et al., 2018, Prediction Machines).
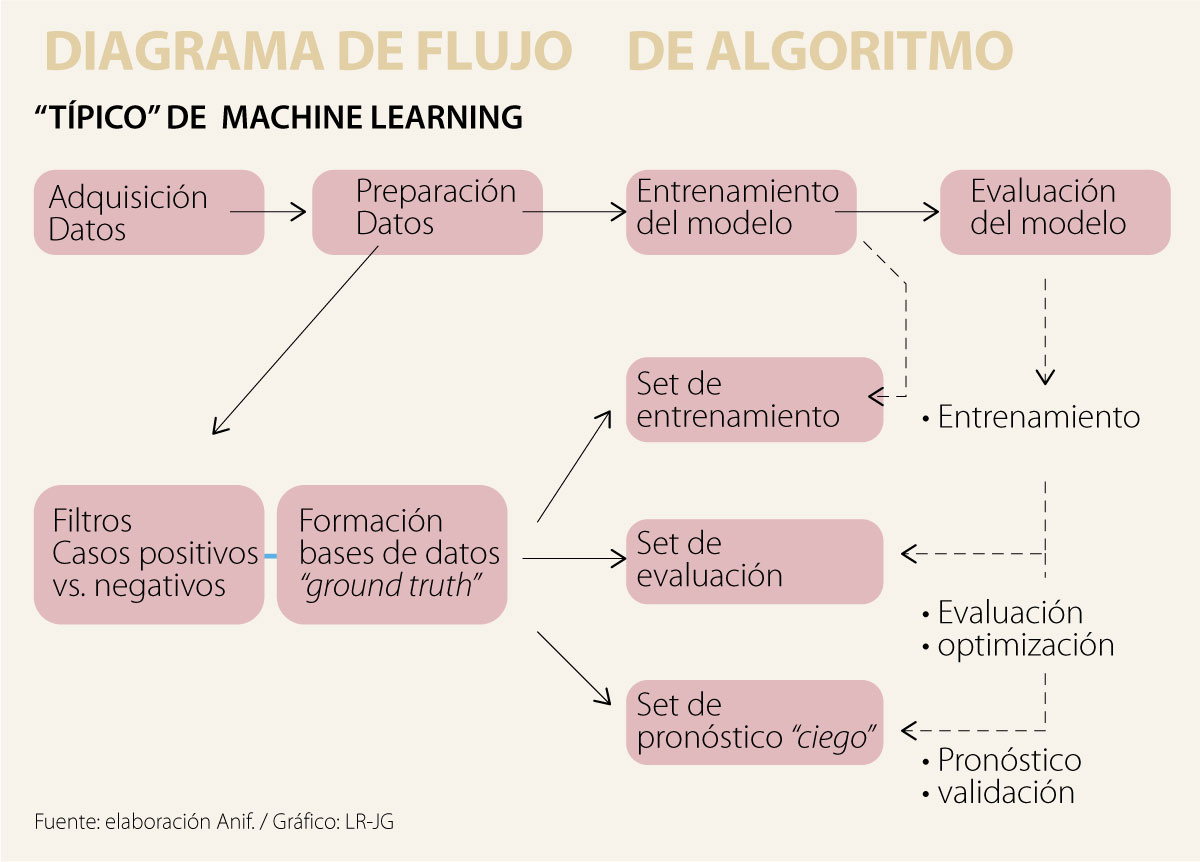
Los análisis de regresión clásicos mostraron sus limitaciones en la crisis de Lehman (2008-2009). En particular, ellos subestimaron las probabilidades del evento subyacente en los Credit Default Obligations (CDOs). Las mismas calificadoras de riesgo asignaban probabilidades de ocurrencia tan bajas como 0,1% a un escenario de pérdidas y mantenían dichas hipotecas como triple-A, ver Lewis (2010), http://anif.co/sites/default/files/lewis_0.pdf.
En esta falla predictiva el error seguramente provino de omitir relaciones clave entre variables de los deudores sub-prime. Precisamente los modelos ML buscan esos “sesgos bayesianos”, los llamados priors. Un ejemplo de correlaciones no anticipadas en los mercados hipotecarios radicó en que los mercados de Phoenix, Las Vegas y Miami se terminaron movien-do al unísono hacia una drástica baja.
La mala noticia es que las técnicas ML aún no están disponibles para el ámbito macro-financiero (ver J.P. Morgan 2018, Machine learning for macro: What you really need to know). A este nivel todavía deben usarse variables tradicionales con muestras limitadas en cobertura y en el tiempo. Si se ilustran predicciones de diferentes familias de modelos, donde los econométricos (univariados y multivariados) aún tienen ventajas frente a las “redes neuronales” o algoritmos ML.
En síntesis, los algoritmos de ML tienen evidentes ventajas de flexibilidad operativa vs. sus contrapartes de regresión clásica. Sin embargo, materializar dichas ventajas requiere de una gran cantidad de datos, muchas veces no disponibles en series de tiempo financieras-macroeconómicas. En otras palabras, dichas aplicaciones ML pueden ser altamente valiosas a la hora de predecir “recomendaciones de películas-series” en Netflix y compras en Amazon, basadas en millones de calificaciones de usuarios; o incluso detectar transacciones fraudulentas en las tarjetas de crédito, con base en millones de transacciones. Sin embargo, su valor agregado en predecir series macrofinancieras mensuales-trimestrales aún es algo limitada.

Una vivienda digna transforma la vida de una familia, fortalece el tejido social y abre oportunidades para las futuras generaciones

Olvidar que el consumidor necesita comprender bien este cambio puede generar una percepción negativa que empañe una migración necesaria







{kind=link}